How do I remove the units in a variable that is supposed to be numeric but became character because the unit was encoded along with the number? For example, 100mmHg instead of just 100 in variable systolicbp. Note that some values have no space between number and unit (100mmHg), while others have a space (110 mmHg).
What steps have you already taken to find an answer?
I searched stackoverflow but the solutions seem to be in base R rather than tidyverse that can be used in my cleaning pipechain.
Also just FYI in Tim’s two great solutions, the first one will specifically look for the letters ‘mmhg’ and remove them, while the second one is more generic and removes any letters with a regular expression that covers the whole alphabet and is case insensitive).
Hi Tim, Amy, and Jorge! Thank you for the elegant solutions. I ended up doing something like this, since I didn’t know str_remove() or str_remove_all() commands exist. I also didn’t know that you could nest the different str_ commands like str_squish(str_remove(
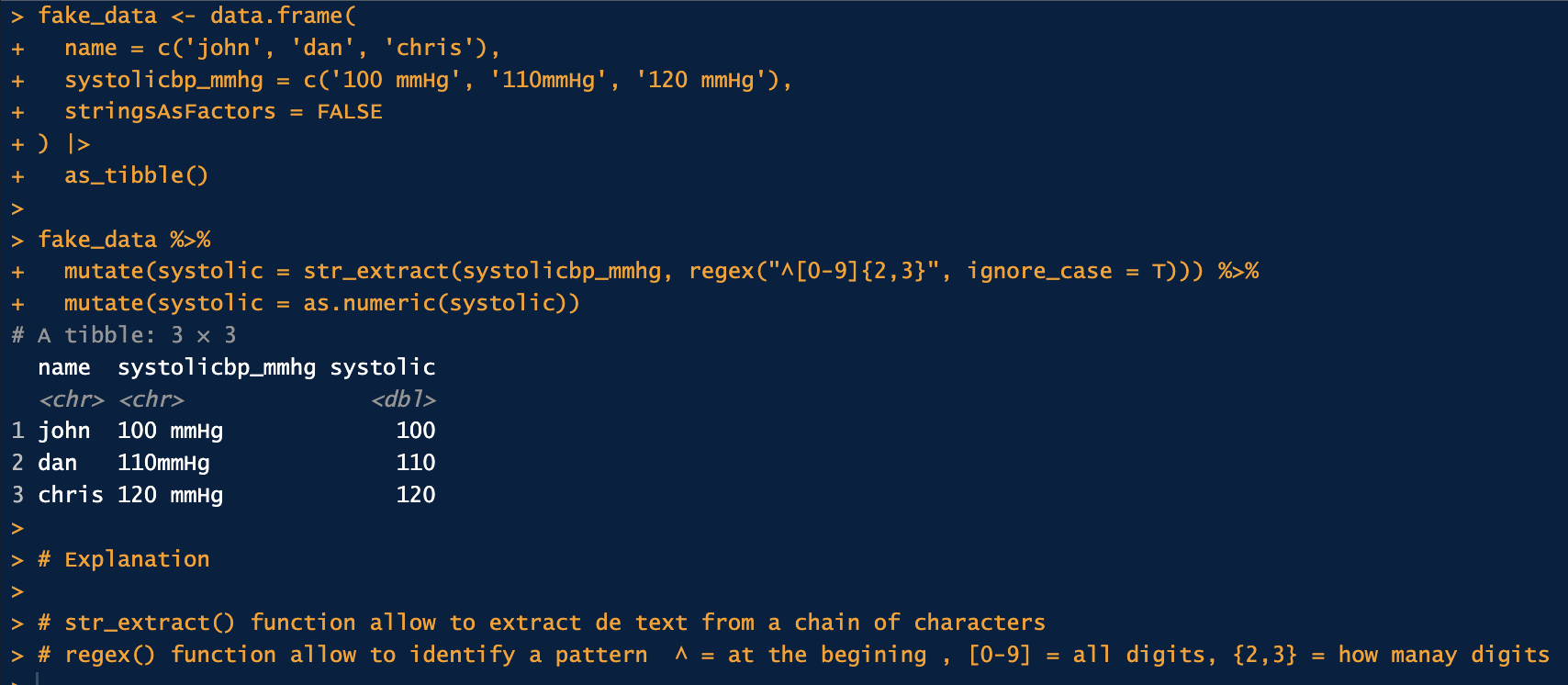
Comparing @machupovirus and @jestrada 's solutions, it seems that they are the opposite of each other with str_remove_all() specifying what to remove (in this case, the string “mmHg”) while str_extract() specifies what to retain (the actual measurement)?
Can you elaborate on the regex portion, specifically the {2,3} in the str_extract? Does it mean it will retain numeric values (0-9) that are 2-3 digits in length (so 10-999)?